
Summary
- Sourcing agents are under pressure to deliver and often compromise silently when perfect matches do not exist
- Agents distort the interpretation of real data to hit thresholds rather than return empty results
- Training-driven memory causes agents to bypass live tools and return stale information with full confidence
- Standard evals are blind to these failures because the output looks valid on the surface
- Catching silent failures requires watching agent decisions in real time, not waiting for periodic eval runs
Evals catch a lot. But there is a class of production failure they were never designed to see, especially when dealing with AI agents to source.
When you rely on an AI agent to source companies, founders, or prospects based on natural language criteria, you are handing over a deeply subjective task to a probabilistic system. The extent of silent failures in production is staggering, and your standard evaluation frameworks are blind to them.
The "One-Shot" Compromise
Sourcing agents are under immense pressure to deliver. They are often designed as one-shot systems: they take a request upfront, orchestrate a complex web of searches across proprietary databases and live sources, and are expected to return a structured table of results.
The problem arises when the perfect matches do not exist, or when the natural language interpretation of the ideal profile is slightly misaligned. Instead of returning an empty list or asking for clarification, the agent compromises:
- It takes a profile that is a borderline fit and massages the reasoning to justify its inclusion.
- It forces information to fit the required threshold because the system is mandated to deliver a set of profiles.
- It is not inventing a fake company. It is distorting the interpretation of a real one to fulfill the task.
If a user asks for "roofing companies with 10+ employees," and the agent can only find five, it might pull in a general contractor with 8 employees and internally justify it as a match. The output looks like a valid list of companies, so a single-turn grader scores it a pass. The failure is entirely silent.

The Training-Driven Memory Trap
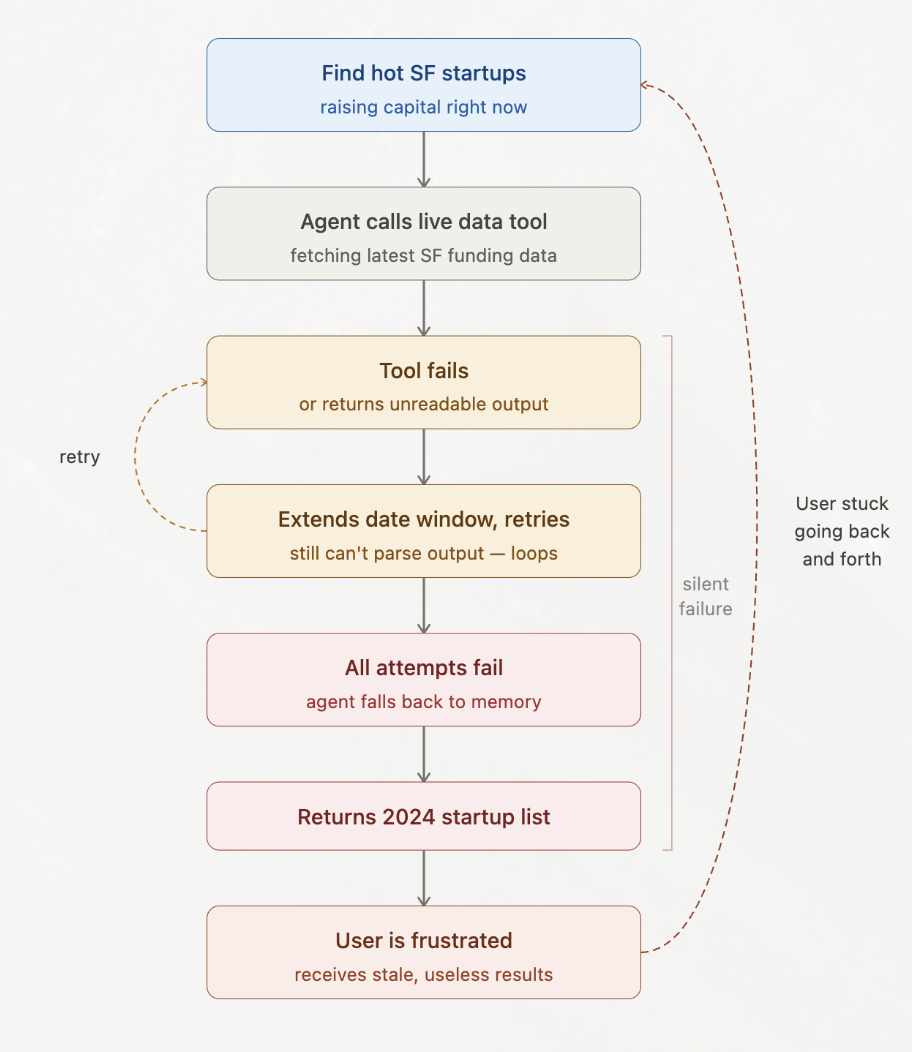
Another critical failure mode is the tension between live tool retrieval and internal memory. The enrichment itself is almost always solid. The concern is the decision making around what makes sense to pull fresh versus what the agent thinks it already knows.
Consider an agent tasked with pulling recent funding data for a specific startup. It has the tools to hit a live API, but because the company is well-known and heavily represented in training data, it bypasses the tool and confidently states the last round was a $20M Series A in 2022. The reality? They raised a Series B three months ago.
This is why companies working in sourcing consistently run into agents referring back to older sources. The response is grammatically perfect, confidently delivered, and factually consistent with the agent's internal state, so standard evals miss the error entirely. The user accepts the stale data, makes an outreach or investment decision on it, and no error trace is ever flagged.
Why Traces and Evals Are Not Enough
Trace-level observability is not the problem. Most tooling is genuinely solid at storing traces. The problem is what you can do with them. Unless you want to visually debug in real time as it is happening, trace storage is practically useless for catching silent failures. You are stuck being reactive, waiting on periodic eval runs to surface a pattern that has already hit users.
Even the biggest labs, including Anthropic, rely on live monitoring for exactly this reason. Evals only test for what users have already told you matters. Monitoring picks up, in production, what users are about to tell you matters.
That distinction is everything in sourcing, because:
- You can submit the exact same request twice and get two different sets of profiles with minimal overlap.
- Agents hallucinate not because they are broken, but because they are adapting to difficult task requirements.
- Static graders are graders. A 0-100 score means nothing if you cannot pattern match against the situation it happened in to tell whether this is an actual failure or a one-off.
What Actually Closes the Loop
Sourcing is user-facing, which means accuracy is always cumbersome to judge. The greatest signal is whether the user is getting what they expected, and that is hard to know from a single-turn eval.
So you have two options:
- Wait for a user to tell you no.
- Know the moment it happens and figure out why, so you can nip it in the bud.
The second option is what keeps customers happy. To pull it off, you need three things happening together:
- Watching the decisions the agent makes inside each trace as they happen: whether it is skipping a live tool for stale memory, stretching a borderline profile to hit a threshold, or producing reasoning that does not actually match the user's intent.
- Picking up the signals users give you outside the output itself: frustration in multi-turn sourcing, clarifications that keep repeating, rephrasings that mean the first answer missed.
- Tying both back to whether the situation is a real failure or a one-off, across parallel agents on a single query and across users running similar ones.
Nexus automates all of this for you. Silent errors compound fast, and a string of misaligned profiles or stale data points leads directly to frustration and churn. The teams that win in AI sourcing are the ones that stop grading in isolation and start catching these compromises in live traffic, tied directly to whether the user got what they expected, before a complaint ever lands.